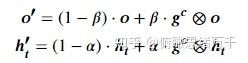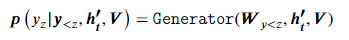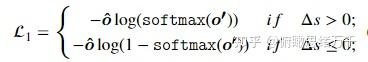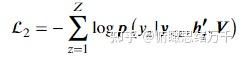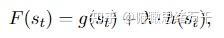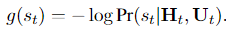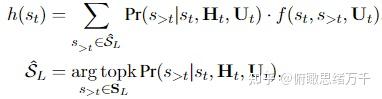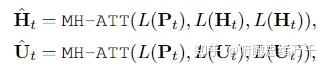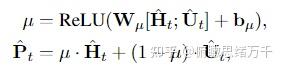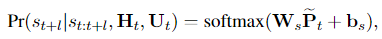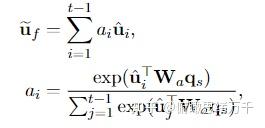这篇文章是情感支持的开山之作,主要有以下两点贡献:
(1)构建了ESConv数据集
(2)将策略引入到情感支持对话中
Control Globally, Understand Locally: A Global-to-Local Hierarchical Graph Network for Emotional Support Conversation
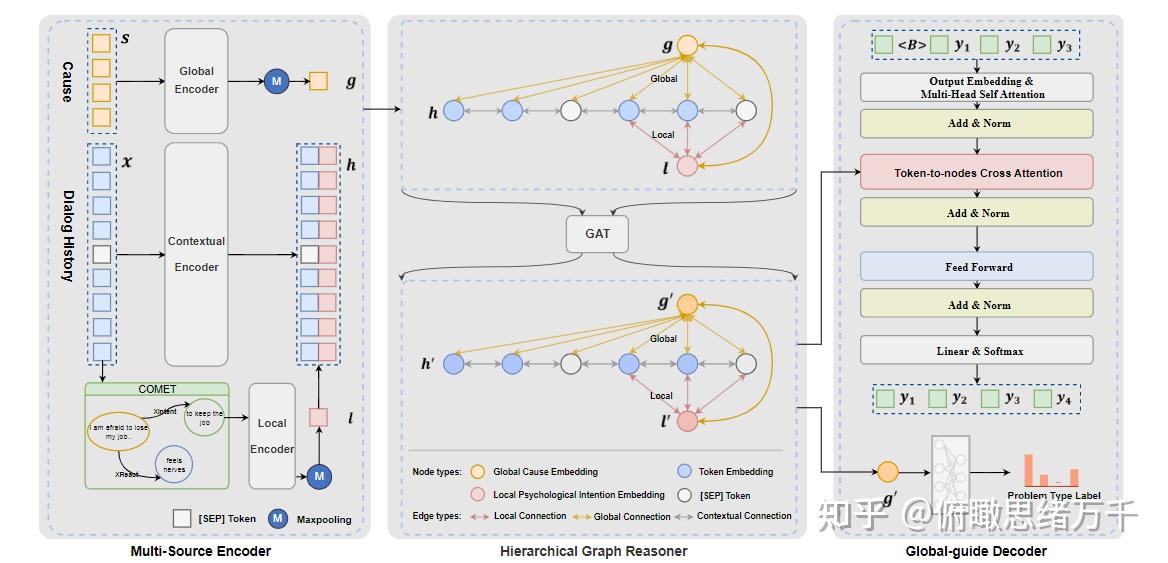
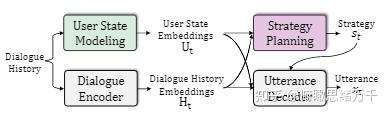
图1
(1)Multi-Source Encoder
捕获全局原因信息和局部心理意图,并对对话历史进行编码。
dialogue history 通过 encoder 得到 ht (对话历史进行编码)
situation information 通过 encoder 得到 g (捕捉全局原因信息)
last utterance 通过 XIntent 得到 inference, 经过编码得到 l (局部心理意图)
ht,g 和 l 都是 d 维,所用的编码器和 BlenderBot 的 encoder 有相同的架构。
(2)Hierarchical Graph Reasoner
生成回复并监督全局原因的语义信息。
token-to-nodes cross attention
使用 problem type of conversation 做为标签,对 g' 做监督学习,g' 为更新后的g。
(4)loss
生成文本的损失 + 交叉熵损失
这篇文章值得借鉴的点有:
(1)引入了局部心理意图信息和全局原因信息。
(2)图模型。
(3)利用 problem type of conversation 做监督学习。
此处有两个疑问:
(1) decoder 时,token-to-nodes cross attention Q K V 分别是什么?可以理解了,是token-to-nodes。
(2)全局原因信息在 interact 时,应该是利用不了的啊,用户应该不会在对话之前提供 situation information
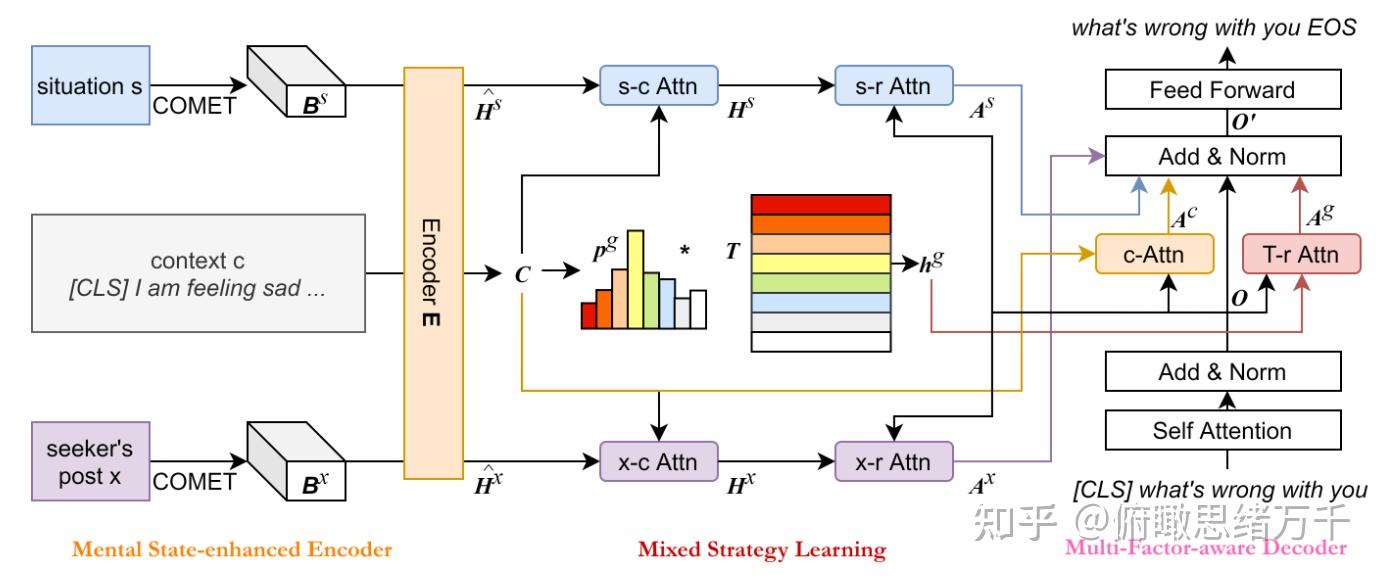
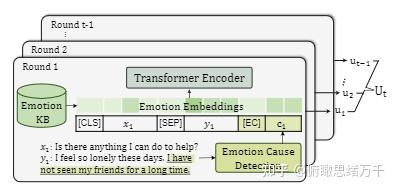
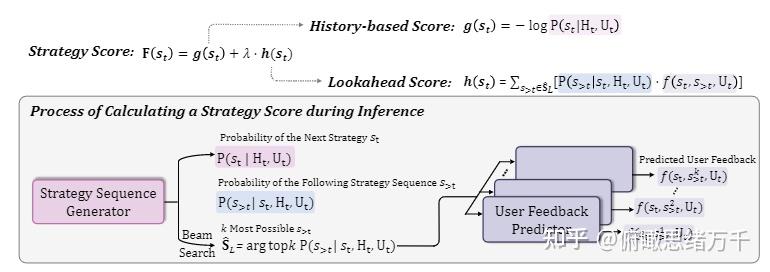
MISC: A MIxed Strategy-Aware Model Integrating COMET for Emotional Support Conversation



 发表于 2023-1-5 12:19:32
发表于 2023-1-5 12:19:32